

Tuanjie 1.6.0版本针对小游戏平台引入了一项令人心动的新能力。通过优化CPU侧的负载,它使得开发者能在保证性能的前提下,制作出场景更加复杂且效果出众的小游戏。这一能力也同时会让iOS、Android等平台有一定的受益。
利用BatchRendererGroup进行快速合批(渲染场景常驻GPU,减少渲染参数提交)
Draw call数量越高、场景越复杂、场景中可GPU实例化的Renderer越多,收益越大
Renderer更新频率越低(如位置、材质变化等),需要更新GPU数据的频率越低,收益越大
针对小游戏平台暂不支持Burst和多线程、C#中的计算开销高于C++的问题,全新实现了一份纯C++版本,以保证性能表现。
在后续的版本中,我们将针对iOS、Android以及PC平台做更好的适配及优化。
开发者能观察到的性能提升,取决于场景的规模和渲染时GPU实例化的程度,GPU实例化对象越多,获得的收益就越大。
开启GPU Resident Drawer的收益同样体现在功耗指标的降低,在多个平台和设备上,我们可以看到功耗数据的喜人变化。
*需要注意的是,在少数旧型号设备上(例如骁龙870),开启GPU Resident Drawer后也可能出现一定的功耗负收益(约100mW),可能和硬件、驱动的支持不完善有关,建议开发者根据实际测试数据权衡选用。
您还可以继续优化设置、局部禁用 GRD 功能、查看优化效果、排查问题等,更多操作请参阅官方指南:
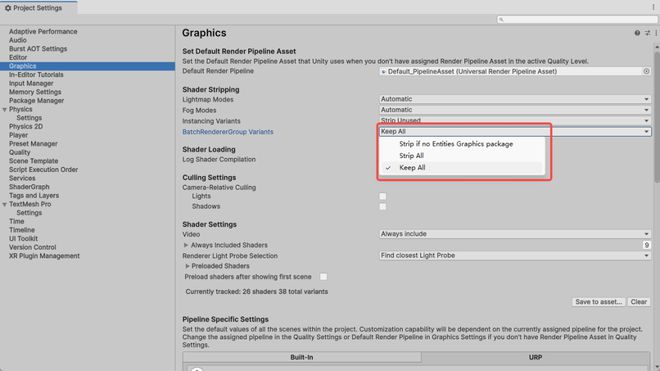
在 URP 管线中,采用 SRP Batcher 可以减少渲染状态的切换,提高渲染效率:
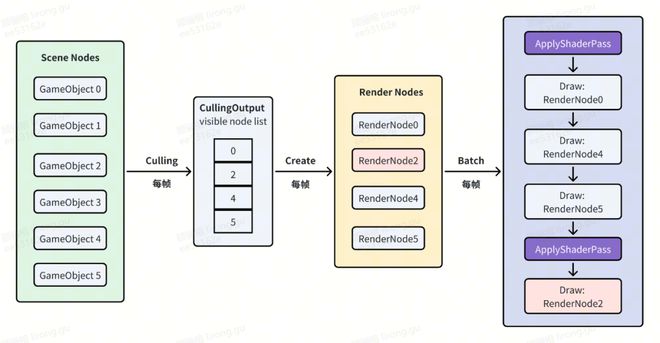
RenderNodes 每帧都会重新创建,但对于静态场景而言,大部分对象几乎不会变化,也就没有必要频繁重新创建 RenderNodes。IM电竞 IM电竞平台IM电竞 IM电竞平台


 15063248823
15063248823

 留言
留言 